Case Study
Rebuilding Our MLOps Foundation for Faster, Safer Forecasting
Introducing a shared Model Contract, MLflow packaging, and a challenger-vs-champion loop that made experimentation fast and deployments boring.
Industry
Renewable energy forecasting
Partner
Platform R&D
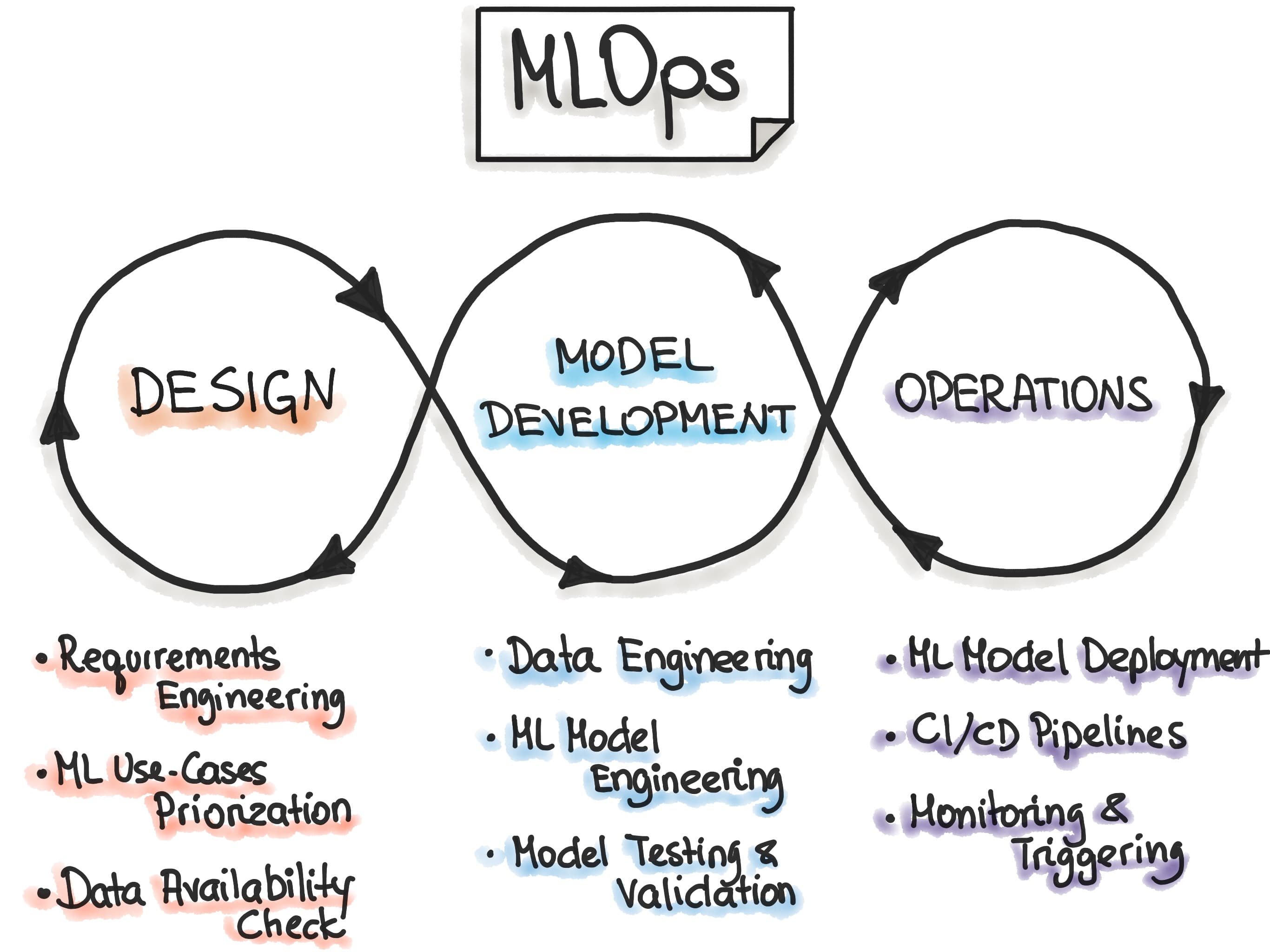
Project Overview
Building breakthrough forecasting models is only half the work. The other half is operational: keeping models deployable, maintainable, and comparable as they evolve. Our research velocity kept climbing, yet the path from notebook to production became fragile. This case study covers how we rebuilt that path so reliability and experimentation could reinforce one another.
Timeline
6 weeks
concept to rollout
Release cadence
+3×
challengers per week
Deploy prep
<1 day
down from 4-5
Why We Needed a New Foundation
As forecasting work scaled across solar, wind, and pricing initiatives, four pressures converged. Data scientists needed freedom to iterate, engineering needed reproducible artefacts, pipelines needed a consistent interface, and the business needed measurable uplifts deployed safely. Our tooling, however, had grown organically. Every model carried slightly different runtimes, packaging rules, and implicit knowledge -meaning a “small” experiment required pipeline surgery.
Data scientists
Wanted to add features or swap dependencies without filing ops tickets or rewriting orchestration logic.
Engineering
Needed deterministic packaging, reproducible environments, and built-in smoke tests before promoting runs.
Pipelines
Required a consistent contract so champions and challengers could be swapped with zero code changes.
The business
Needed measurable improvements -like nMAE reductions -rolled out safely and predictably.
Our goal became simple: make experimentation fast, and deployment boring.
The Turning Point: A Shared Model Contract
We introduced a Model Contract -an explicit definition of what every model must provide. The contract sits inside the artifact, so when a model loads, its expectations travel with it. Pipelines stop relying on tribal knowledge; the model describes itself.
What the contract includes
- Input schema and feature query logic
- Output structure, quantiles, and metadata
- Runtime requirements (Python/CUDA/env vars)
- Packaging + health-check rules
What it unlocked
- Instant schema drift detection
- Comparable assumptions across generations
- Pipelines agnostic to architecture
- Faster onboarding for new contributors
Standardising Packaging with MLflow
Next, we adopted MLflow’s `pyfunc` interface as the universal packaging format. Every artifact now carries the contract, model weights, dependencies, inference logic, and lineage metadata. The exact same bundle is used for local experiments, challenger evaluation, CI/CD testing, and production inference.
Package once, run anywhere
- No bespoke Dockerfiles per experiment
- CI loads artifacts exactly like prod
- Blue/green deploys are MLflow URI swaps
- Rollbacks are instant registry pointer changes
Operational gains
- Research ↔ deployment parity
- Automated dependency locking
- Cross-team sharing via registry IDs
- Consistent smoke tests + health checks
Introducing the Challenger vs. Champion Loop
Forecasting gains are rarely obvious in a single notebook run. Different weather regimes, asset classes, and time horizons can flip a “better” model into a regression. We implemented a rigorous challenger-vs-champion process so only consistently superior challengers advance.
- Champion snapshot pinned from the production registry.
- Any new candidate registers as a challenger with its contract + metadata.
- Both run on identical data slices through the same inference pipelines.
- Metrics compare accuracy, stability, edge-case handling, and runtime cost.
- Promotion requires the challenger to outperform the champion across multiple weeks.
Because every model shares the contract + MLflow format, we can compare older architectures vs. newer ones, different feature sets, alternate weather providers, and even physics-informed hybrids -without rewriting code or pipelines.
What This Enabled
The Result
We now operate on an MLOps foundation that supports rapid renewable forecasting research without compromising reliability. Models can evolve dramatically while the system around them stays stable. The same scaffolding powers ongoing initiatives -from advanced physics integrations to multi-model ensembles -ensuring innovation and operational safety move in lockstep.
Innovation can happen quickly, and production remains stable.
Reliability and experimentation no longer compete -they reinforce each other. Ready to build something similar? Let’s talk.
Book a short assessment →